


UPDATE, August 2024: Voice AI moves fast! We’ve updated our demo since this post was published a few weeks ago. The links below are edited, to point to our updated ultra low latency demo. We built the original demo on Cerebrium’s excellent serverless infrastructure.
Speed is important for voice AI interfaces. Humans expect fast responses in normal conversation – a response time of 500ms is typical. Pauses longer than 800ms feel unnatural.
Source code for the bot is here. And here is a demo you can interact with.
Technical tl;dr
Today’s best transcription models, LLMs, and text-to-speech engines are very good. But it’s tricky to put these pieces together so that they operate at human conversational latency. The technical drivers that are most important, when optimizing for fast voice-to-voice response times are:
- Network architecture
- AI model performance
- Voice processing logic
Today’s state-of-the-art components for the fastest possible time to first byte are:
- WebRTC for sending audio from the user’s device to the cloud
- Deepgram’s fast transcription (speech-to-text) models
- Llama 3 70B or 8B
- Deepgram’s Aura voice (text-to-speech) model
In our original demo, we self-host all three AI models – transcription, LLM, and voice generation – together in the same Cerebrium container. Self-hosting allows us to do several things to reduce latency.
- Tune the LLM for latency (rather than throughput).
- Avoid the overhead of making network calls out to any external services.
- Precisely configure the timings we use for things like voice activity detection and phrase end-pointing.
- Pipe data between the models efficiently.
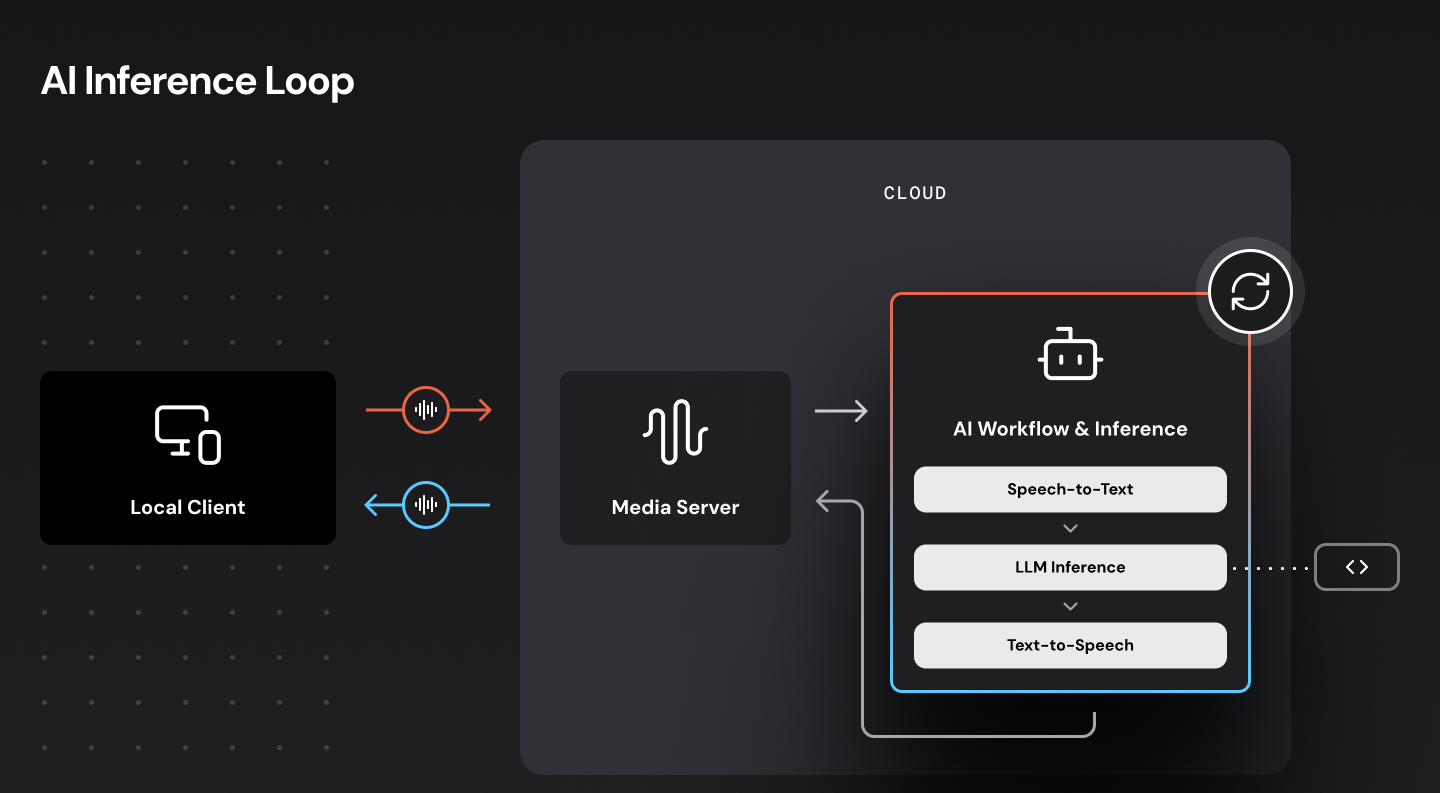
We are targeting an 800ms median voice-to-voice response time. This architecture hits that target and in fact can achieve voice-to-voice response times as low as 500ms.
Optimizing for low latency: models, networking, and GPUs
The very low latencies we are targeting here are only possible because we are:
- Using AI models chosen and tuned for low latency, running on fast hardware in the cloud.
- Sending audio over a latency-optimized WebRTC network.
- Colocating components in our cloud infrastructure so that we make as few external network requests as possible.
AI models and latency
All of today’s leading LLMs, transcription models, and voice models generate output faster than humans speak (throughput or tokens per second). So we don’t usually have to worry much about our models having fast enough throughput.
On the other hand, most AI models today have fairly high latency relative to our target voice-to-voice response time of 500ms. When we are evaluating whether a model is fast enough to use for a voice AI use case, the kind of fast we’re measuring and optimizing is the latency kind.
We are using Deepgram for both transcription and voice generation, because in both those categories Deepgram offers the lowest-latency models available today. Additionally, Deepgram’s models support “on premises” operation, meaning that we can run them on hardware we configure and manage. This gives us even more leverage to drive down latency. (More about running models on hardware we manage, below.)
Deepgram’s Nova-2 transcription model can deliver transcript fragments to us as quickly as 100ms. Deepgram’s Aura voice model running in our Cerebrium infrastructure has a time to first byte as low as 80ms. These latency numbers are very good! The state of the art in both transcription and voice generation are rapidly evolving, though. We expect lots of new features, new commercial competitors, and new open source models to ship in 2024 and 2025.
Llama 3 70B is among the most capable LLMs available today. We’re running Llama 3 70B on NVIDIA H100 hardware, using the vLLM inference engine. This configuration can deliver a median time to first token (TTFT) latency of 80ms. The fastest hosted Llama 3 70B services have latencies approximately double that number. (Mostly because there is significant overhead in making a network request to a hosted service.) Typical TTFT latencies from larger-parameter SOTA LLMs are 300-400ms.
WebRTC networking for voice AI
WebRTC is the fastest, most reliable way to send audio and video over the Internet. WebRTC connections prioritize low latency and the ability to adapt quickly to changing network conditions (for example, packet loss spikes). For more information about the WebRTC protocol and how WebRTC and WebSockets complement each other, read this short explainer.
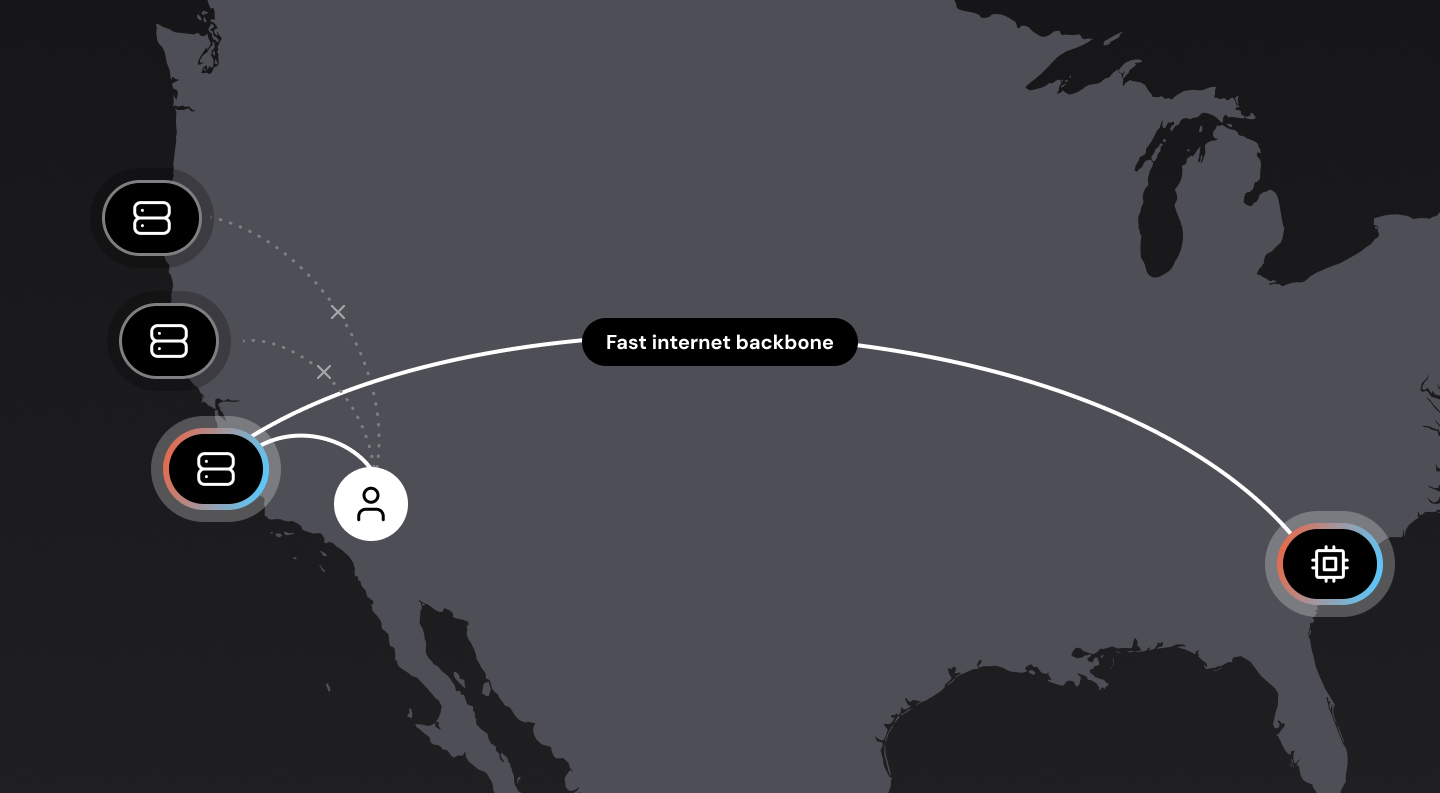
Connecting users to nearby servers is also important. Sending a data packet round-trip between San Francisco and New York takes about 70ms. Sending that same packet from San Francisco to, say, San Jose takes less than 10ms.
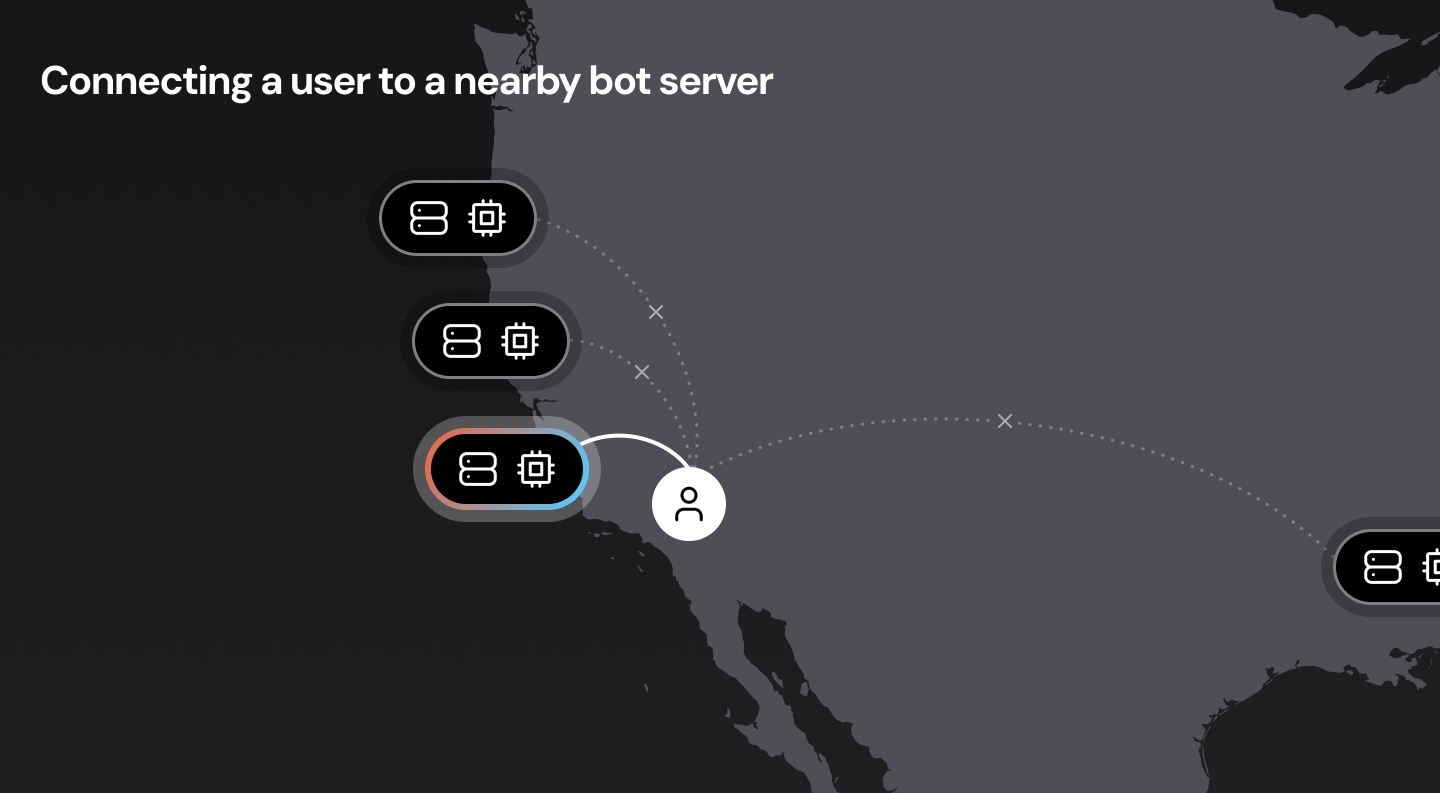
In a perfect world, we would have voice bots running everywhere, close to all users. This may not be possible, though, for a variety of reasons. The next best option is to design our network infrastructure so that the “first hop” from the user to the WebRTC cloud is as short as possible. (Routing data packets over long-haul Internet connections is significantly slower and more variable than routing data packets internally over private cloud backbone connections.) This is called edge or mesh networking, and is important for delivering reliable audio at low latency to real-world users. If you’re interested in this topic, here’s a deep dive into WebRTC mesh networking.
Where the components run – self-hosting the LLM and voice models
The code for an AI voice bot is usually not terribly large or complicated. The bot code manages the orchestration of transcription, LLM context-management and inference, and text-to-speech voice generation. (In many applications, the bot code will also read and write data from external systems.)
But, while voice bot logic is often simple enough to run locally on a user’s mobile device or in a web browser process, it almost always makes sense to run voice bot code in the cloud.
- High-quality, low-latency transcription requires cloud computing horsepower.
- Making multiple requests to AI services – transcription, LLM, text-to-speech – is faster and more reliable from a server in the cloud than from a user’s local machine.
- If you are using external AI services you need to proxy them or access them only from the cloud to avoid baking API keys into client applications.
- Bots may need to perform long-running processes, or may need to be accessible via telephone as well as browser/app.
Once you are running your bot code in the cloud, the next step in reducing latency is to make as few requests out to external AI services as possible. We can do this by running the transcription, LLM, and text-to-speech (TTS) models ourselves, on the same computing infrastructure where we run the voice bot code.
Colocating voice bot code, the LLM, and TTS in the same infrastructure saves us 50-200ms of latency from network requests to external AI services. Managing the LLM and TTS models ourselves also allows us to tune and configure them to squeeze out even more latency gains.
The downside of managing our own AI infrastructure is additional cost and complexity. AI models require GPU compute. Managing GPUs is a specific devops skill set, and cloud GPU availability is more constrained than general compute (CPU) availability.
Voice AI latency summary – adding up all the milliseconds
So, if we’re aiming for 800ms median voice-to-voice latency (or better) what are the line items in our latency “budget?”
Here’s a list of the processing steps in the voice-response loop. These are the operations that have to be performed each time a human talks and a voice bot responds. The numbers in this table are typical metrics from our reasonably well optimized demo running on NVIDIA containers hosted by Cerebrium.

Next steps
For some voice agent applications, the cost and complexity of managing AI infrastructure won’t be worth taking on. It’s relatively easy today to achieve voice-to-voice latency in the neighborhood of two to four seconds using hosted AI services. If latency is not a priority, there are many LLMs that can be accessed via APIs and have time to first token metrics of 500-1500ms. Similarly, there are several good options for transcription and voice generation that are not as fast as Deepgram, but deliver very high quality text-to-speech and speech-to-text.
However, if fast, conversational voice responsiveness is a primary goal, the best way to achieve that with today’s technology is to optimize and colocate the major voice AI components together.
If this is interesting to you, definitely try out the demo, read the demo source code (and experiment with the Pipecat open source voice AI framework), and learn more about Cerebrium's fast and scalable AI infrastructure.
Never miss a story
Get the latest direct to your inbox.