Daily’s developer platform powers audio and video experiences for millions of people all over the world. Our customers are developers who use our APIs and client SDKs to build audio and video features into applications and websites.
Today, as part of AI Week, we’re talking about building voice-driven AI applications.
Our kickoff post for AI Week goes into more detail about what topics we’re diving into and how we think about the potential of combining WebRTC, video and audio, and AI. Feel free to click over and read that intro before (or after) reading this post.
Lately, we’ve been doing a lot of experimenting and development with the newest AI large language models (LLMs). We’ve shipped products that use GPT-4. We’ve helped customers build features that leverage several kinds of smaller, specialized models. We’ve developed strong opinions about which architectures work best for which use cases. And we have strong opinions about how to wire up real-time audio and video streams bidirectionally to AI tools and services.
We built a little demo of an LLM that tells you a choose-your-own-adventure story, alongside DALL-E generative art. The demo is really, really fun. Feel free to go play with it now and talk with the LLM to generate a story!
If you have such a good time that you don’t make it back here, just remember these three things for when you start building your own voice-driven LLM app:
- Run everything in the cloud (if you can afford to)
- Don’t use web sockets for audio or video transport (if you can avoid them)
- Squeeze every bit of latency you can out of your data flow (because users don’t like to wait)
The demo is built on top of our daily-python SDK. Using the demo as a starting point, it should be easy to stand up a voice-driven LLM app on any cloud provider. If you’re just here for sample code (you know who you are) just scroll to the bottom of this post.
If you’re more in a lean back mode right now, you can also watch this video that Annie made, walking through the demo. (In her adventure, the LLM tells a story about a brave girl who embarks on a quest — aided by a powerful night griffin — to free her cursed kingdom.)
In this post, we'll take a look at the architecture and work behind the demo, covering:
3 components to build an LLM application | data flow | speech-to-text: client-side or in the cloud? | web sockets or WebRTC | where to run your app's speech-to-LLM-to-speech logic | phrase detection and endpointing | LLM-prompting APIs, and streaming the response data | natural sounding speech synthesis | how hard can audio buffer management be? | using llm-talk to build voice-driven LLM apps
Let's dive in.
Frontier LLMs are good conversationalists
There’s a lot of really cool stuff that today’s newest, most powerful, “frontier” large language models can do. They are good at taking unstructured text and extracting, summarizing, and structuring it. They’re good at answering questions, especially when augmented with a knowledge base that’s relevant to the question domain. And they’re surprisingly good conversationalists!
At Daily, we’re seeing a lot of interesting use cases for conversational AI: teaching and tutoring, language learning, speech-to-speech translation, interview prep, and a whole host of experiments with creative chatbots and interactive games.
You need three basic components to get started building an LLM application:
- Speech-to-text (abbreviated as STT, and also called transcription or automatic speech recognition)
- Text-to-speech (abbreviated as TTS, and also called voice synthesis)
- The LLM itself
Interestingly, all of these are “AI.” The underlying technology for state- of-the-art speech-to-text models, text-to-speech models, and large language models are quite similar.
Data flow
Here are the processing and networking steps common to every speech-to-speech AI app.
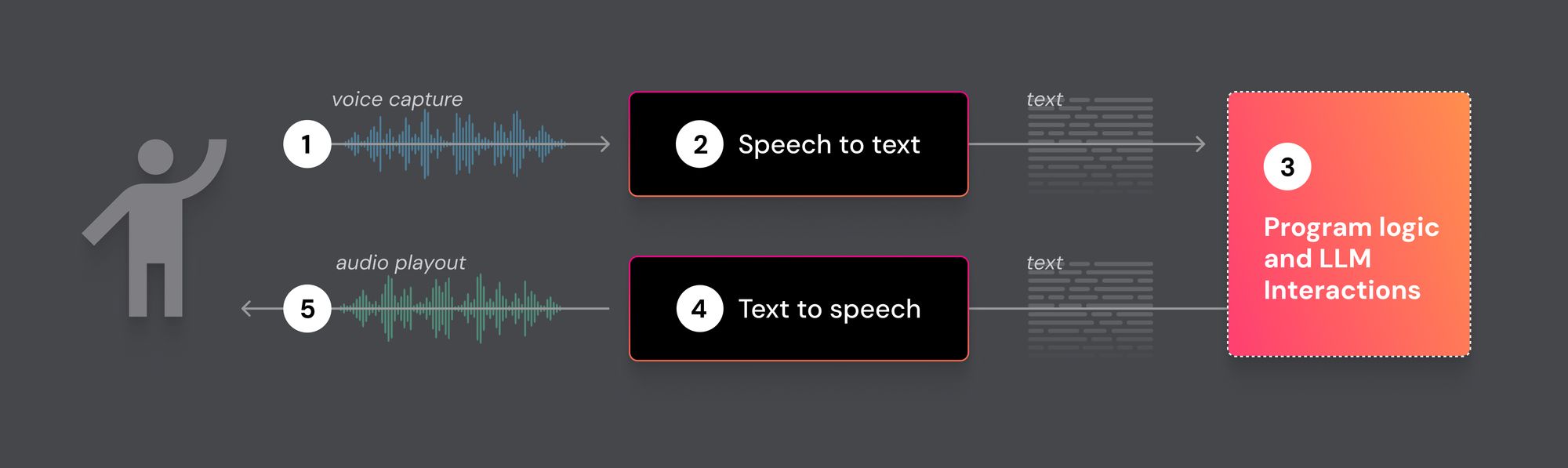
- Voice capture
- Speech-to-text
- Text input to LLMs (and possibly other AI tools and services)
- Text-to-speech
- Audio playout
These are the low-level, generic building blocks that you’ll need. All the specific design and logic that makes an application unique — how the UX is designed, how you prompt the LLM, the workflow, unique data sets, etc — are built on top of these basic components.
Some considerations (things that can be tricky)
You can hack together a speech-to-speech app prototype pretty quickly, these days. There are lots of easy-to-use libraries for speech recognition, networking, and voice synthesis.
If you’re building a production application, though, there are a few things that can take a lot of time to debug and optimize. There are also some easy-to-get-started-with approaches that are likely to be dead-ends for production apps at scale.
Let’s talk about a few choices and tradeoffs, and a few things that we’ve seen trip people up as they move from prototyping into production and scaling.
Speech-to-text – client-side or in the cloud?
Your first technology decision is whether to run speech-to-text locally on each user’s device, or whether to run it in the cloud. Local speech recognition has gotten pretty good. Running locally doesn’t cost any money, whereas using a cloud STT service does.
But local speech recognition today is not nearly as fast or as accurate as the best STT models running on big, optimized, cloud infrastructure. For many applications, speech-to-text that is both as fast as possible and as accurate as possible is make-or-break. One way to think about this is that the output of speech recognition is the input to the LLM. The better the input to the LLM, the better the LLM can perform.
For both speed and accuracy, we recommend Deepgram. We benchmark all of the major speech services regularly. Deepgram consistently wins on both speed and accuracy. Their models are also tunable if you have a specific vocabulary or use case that you need to hyper-optimize for. Because Deepgram is so good, we’ve built a tightly coupled Deepgram integration into our SFU codebase, which helps just a little bit more in reducing latency.
Azure, GCP, and AWS all have invested recently in improving their ASR (Automatic Speech Recognition) offerings. So there are several other good options if for some reason you can’t use Deepgram.
Web sockets or WebRTC?
Getting audio from a user’s device to the cloud means compressing it, sending it over a network channel to your speech-to-text service of choice, and then receiving the text somewhere you can process it.
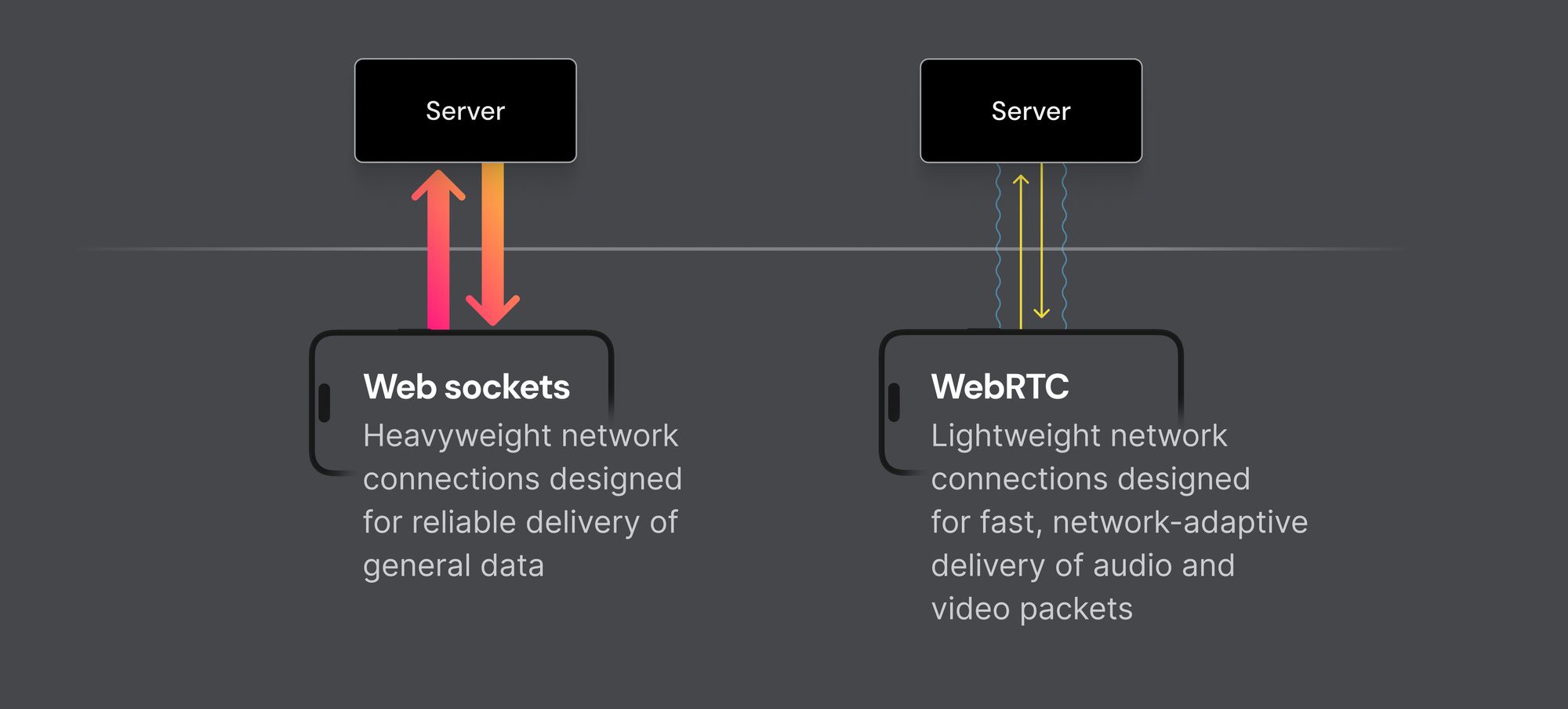
One option for sending audio over the internet is to use web sockets. Web sockets are widely supported by both front-end and back-end development frameworks and generally work fine for audio streaming when network conditions are ideal.
But web socket connections will run into problems streaming audio under less-than-ideal network conditions. In production, a large percentage of users have less-than-ideal networks!
Web sockets are an abstraction built on top of TCP, which is a relatively complex networking layer designed to deliver every single data packet as reliably as possible. Which sounds like a good thing, but turns out not to be when real-time performance is the priority. If you need to stream packets at very low latency, it’s better to use a faster, simpler network protocol called UDP.
These days, the best choice for real-time audio is a protocol called WebRTC. WebRTC is built on top of UDP and was designed from the ground up for real-time media streaming. It works great in web browsers, in native desktop apps, and on mobile; and its standout feature is that it’s good at delivering audio and video at real-time latency across a very wide range of real-world network connections.
Some things that you get with WebRTC that are difficult or impossible to implement on top of web sockets include:
- Selectively resending dropped packets based on whether they’re likely to arrive in time to be inserted into the playout stream
- Dynamic feedback from the network layer to the encoding layer of the media stack, so the encoding bitrate can adapt on the fly to changing network conditions
- Hooks for the monitoring and observability that you need in order to understand the overall performance of media delivery to your end users
There’s a lot of really cool stuff to talk about in this domain. If you are interested in reading more about the trade-offs involved in designing protocols for real-time media streaming, see our in-depth post about WebRTC, HLS, and RTMP.
WebRTC is a significant improvement over web sockets for audio. Using WebRTC is a necessity for video.
Video uses much more network bandwidth than audio, so dropped and delayed packets are more frequent. Video codecs also can’t mitigate packet loss as well as audio codecs can. (Modern audio codecs use nifty math and can be quite robust in the face of partial data loss). But WebRTC’s bandwidth adaptation features enable reliable video delivery on almost any network.
WebRTC also makes it easy to include multiple users in a real-time session. So, for example, you can invite our storybot demo to join a video call between a child and her grandparents.
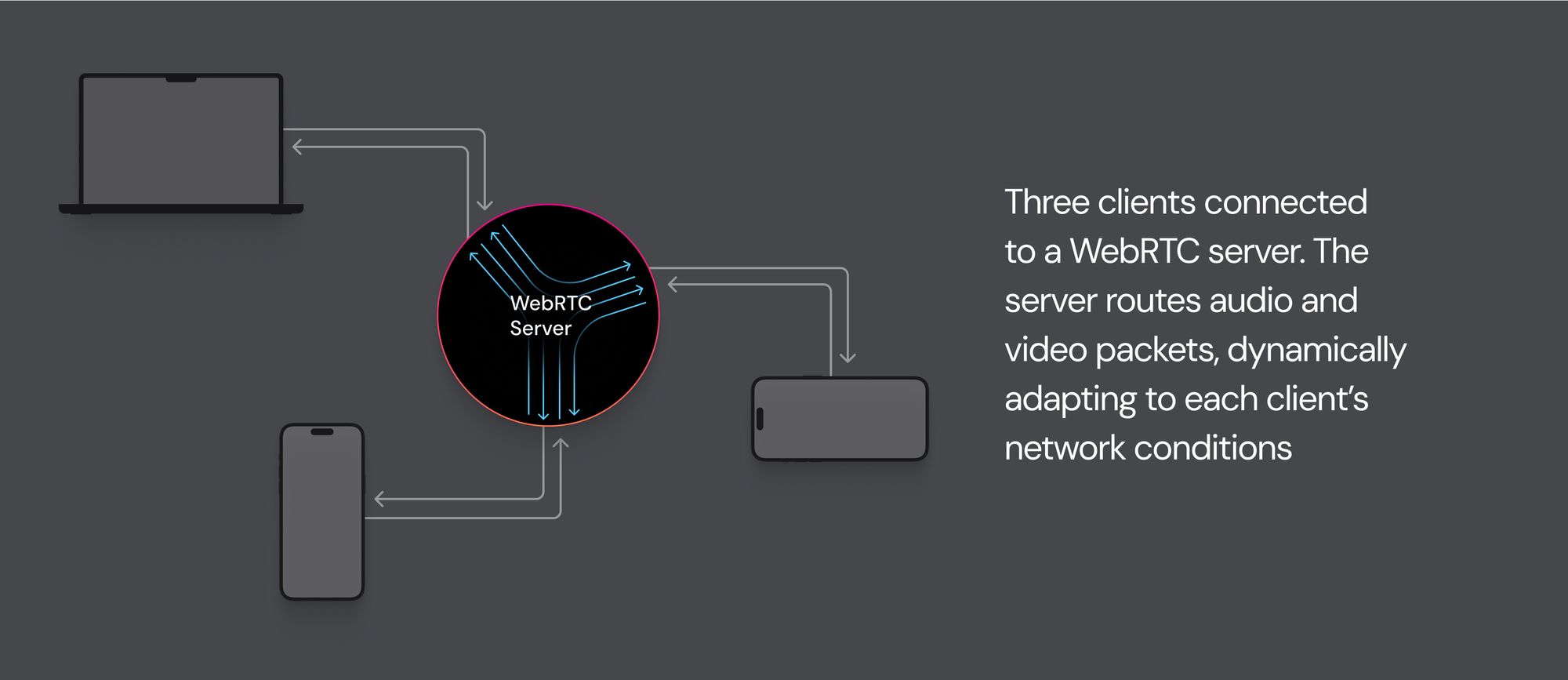
Where to run your app’s speech-to-LLM-to-speech logic
Should you run the part of your application logic that glues together speech-to-text, an LLM, and text-to-speech locally or in the cloud?
Running everything locally is nice. You’re just writing one program (the code running on the user’s device). The downside of running everything locally is that for each piece of the conversation between the user and the LLM, you are making three network connections from the user’s device to the cloud.
The alternative is to move some of your application logic into the cloud.
Here are two diagrams, showing the difference (local on left; cloud on right).
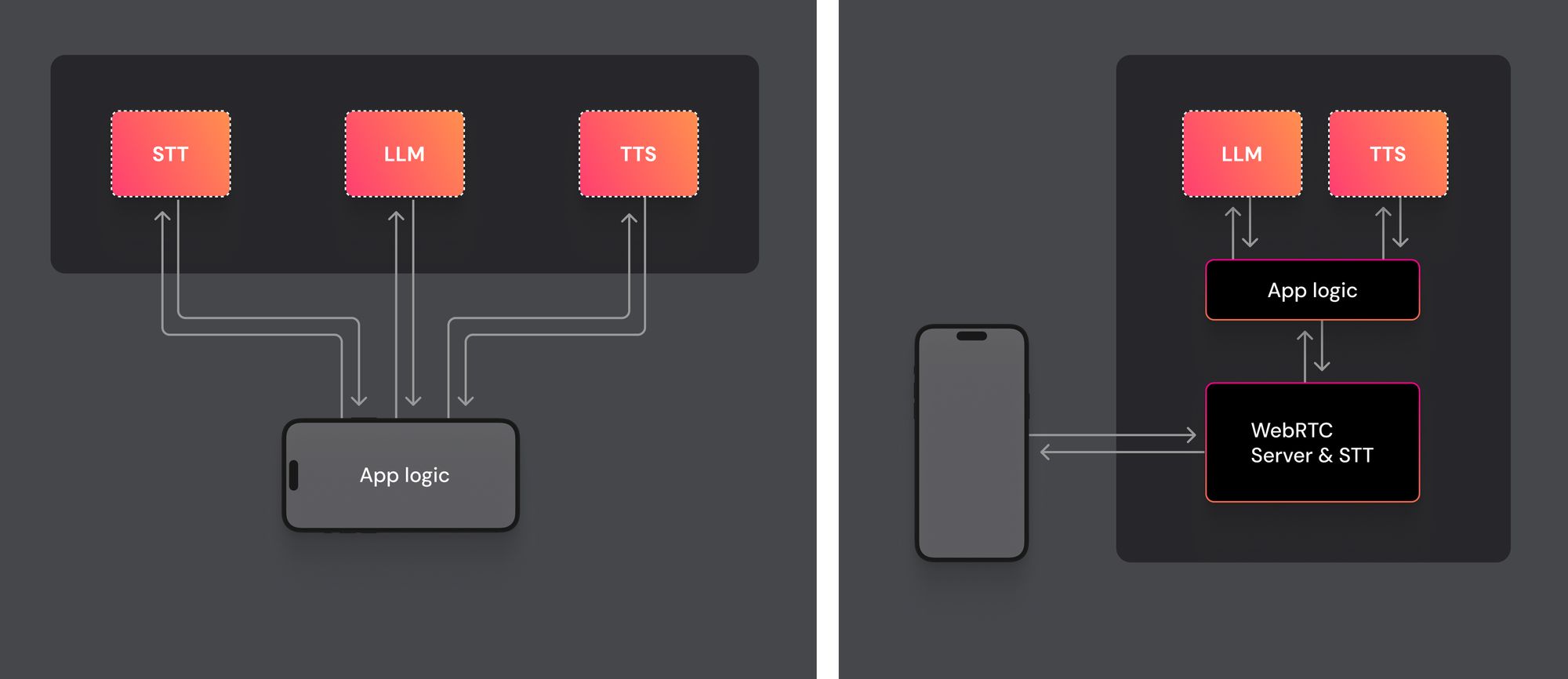
In general, moving part of your application code into the cloud will improve reliability and lower latency.
This is especially true for users with not-great network connections. And it’s especially, especially true if the user is in a different geographic region from the infrastructure that your services are running on.
We have a lot of data on this kind of thing at Daily, and the performance improvements that come from doing as few “first-mile” round trips as possible varies a great deal between different user cohorts and geographies. But for an average user in the US, the six network connection arrows in the left diagram would typically add up to a total latency of about 90ms. For the same average user, the eight network connection arrows in the right diagram would typically add up to about 55ms.
Moving some of your application logic into the cloud has other benefits in addition to reducing total latency. You control the compute and network available to your app in the cloud. So you can do things in the cloud that you simple can’t do locally. For example, you can run your own private LLM – say, the very capable Llama2 70B – inside the app logic box in the right diagram!
Phrase detection and endpointing
Once voice data is flowing through your speech-to-text engine, you’ll have to figure out when to collect the output text and prompt your LLM. In the academic literature, various aspects of this problem are referred to as “phrase detection,” “speech segmentation,” and “endpointing.” (The fact that there is academic literature about this is a clue that it’s a non-trivial problem.)

Most production speech recognition systems use pauses (the technical term is, “voice activity detection”), plus some semantic analysis, to identify phrases.
Sometimes humans pause . . . and then keep talking. (This is called "barge-in.") To handle that case, it’s useful to build logic into your app that allows you to interrupt the LLM query or the text to speech output and restart the data flow.
Note that in the demo app, we have a hook for implementing barge-in, but it's not actually wired up yet. We're using a combination of client- and server-side logic to manage conversation flow. On the client side, we're using JavaScript audio APIs to monitor the input level of the microphone to determine when the user has started and stopped talking. On the server side, Deepgram's transcription includes endpointing information in the form of end-of-sentence punctuation. We use both of those signals to determine when the user is done talking, so we can play the chime sound and continue the story.
LLM prompting APIs, and streaming the response data
A subtle, but important, part of using today’s large language models is that the APIs and best practices for usage differ for different services and even for different model versions released by the same company.
For example, GPT-4’s chat completion API expects a list of messages, starting with a system prompt and then alternating between “user” and “assistant” (language model) messages.
messages=[
{"role": "system", "content": "You are a storyteller who loves to make up fantastic, fun, and educational stories for children between the ages of 5 and 10 years old. Your stories are full of friendly, magical creatures. Your stories are never scary. Stop every few sentences and give the child a choice to make that will influence the next part of the story. Begin by asking what a child wants you to tell a story about. Then stop and wait for the answer.."},
{"role": "assistant", "content": ""What would you like me to tell a story about? Would you like a fascinating story about brave fairies, a happy tale about a group of talking animals, or an adventurous journey with a mischievous young dragon?""},
{"role": "user", "content": "Talking animals!"}
]
We’ve often seen developers who are using the GPT-4 API for the first time put their entire prompt into a single “user” message. But it’s frequently possible to get better results using a “system” prompt and a series of messages entries, especially for multi-turn interactions.
Using a “system” prompt also helps maintain the predictability, tone, and safety of the LLM’s output. This technology is so new that we don’t yet know how to make sure that LLMs stay on task (as defined by the application developer). For some background, see this excellent overview by Simon Willison.
To keep latency low, it’s important to use any streaming mode configurations and optimizations that your service supports. You’ll want to write your response handling code to process the data as individual, small chunks, so that you can start streaming to your text-to-speech service as quickly as possible.
It's also worth thinking about ways you can actually use the capabilities of the LLM to your advantage. LLMs are good at outputting structured and semi-structured text. In our demo code, we're instructing the LLM to insert a break word between the "pages" of the story. When we see that break word as we're processing the streaming response from the LLM, we know we can send that portion of the story to TTS.
Natural-sounding speech synthesis
As is the case with text-to-speech, you can run speech-to-text locally on a user’s computer or phone, but you probably don’t want to. State of the art, cloud TTS services produce output that sounds significantly more natural and less robotic than the best local models, today.
There are several good options for cloud TTS. We usually recommend Azure Speech or Elevenlabs. The landscape is evolving rapidly, though, and there are frequent and exciting updates and new contenders.
GPT-4 and other top-performing LLMs are good at streaming their completion data at a consistent rate, without big delays in the middle of a response. (And if you’re running your processing code in the cloud, network-related delays will be very rare.) So for many applications, you can just feed the streaming data directly from your LLM into your text- to-speech API.
But if you are filtering or processing the text from the LLM, before sending it to TTS, you should think about whether your processing can create temporal gaps in the data stream. Any gaps longer than a couple hundred milliseconds will be audible as gaps in the speech output.
How hard can audio buffer management be?
Finally, once you have an audio stream coming back from your text to speech service, you’ll need to send that audio over the network. This involves taking the incoming samples, possibly stripping out header metadata, then shuffling the samples into memory buffers you can hand over to your low-level audio encoding and network library.
Here, I’ll pause to note that I’ve written code that copies audio samples from one data structure in memory to some other data structure in memory at least a couple of hundred times during my career and in at least half a dozen different programming languages.
Yet still, when I write code like this from scratch, there’s usually at least one head-scratching bug I have to spend time tracking down. I get the length of the header that I’m stripping out wrong. My code works on macOS but initially fails in a Linux VM because I didn’t think about endianness. I don’t know the Python threading internals well enough to avoid buffer underruns. Sample rate mismatches. Etc etc.
Sadly, GPT-4 code interpreter and Github Copilot don’t yet just write bug free audio buffer management functions for you. (I know, because I tried with both tools last week. Both are very impressive – they can provide guidance and code snippets in a way that I would not have believed possible a few months ago. But neither produced production ready code even with some iterative prompting.)
Which brings us to the framework code we wrote to help make all of the tricky things described above a little bit easier.
Using our llm-talk sample code to build voice-driven LLM apps
We’ve posted the source code for this demo in a github repo called llm-talk. The repo includes both a bunch of useful sample code for building a voice-driven app, and orchestrator framework code that tries to abstract away a lot of the low-level functionality common to most voice-driven and speech-to-speech LLM apps.
- All this code is written on top of our
daily-pythonSDK and leverages Daily’s global WebRTC infrastructure to give you very low-latency connectivity most places around the world - Deepgram speech to text capabilities are integrated into Daily’s infrastructure
- Probable phrase endpoints are marked in the speech-to-text event stream
- Orchestrator methods include support for restarting both LLM inference and speech synthesis
- The library handles audio buffer management (and threading) for you
Here’s some sample code from daily-llm.py, showing how we're joining a Daily call and listening for transcription events.
def configure_daily(self):
Daily.init()
self.client = CallClient(event_handler = self)
self.mic = Daily.create_microphone_device("mic", sample_rate = 16000, channels = 1)
self.speaker = Daily.create_speaker_device("speaker", sample_rate = 16000, channels = 1)
self.camera = Daily.create_camera_device("camera", width = 512, height = 512, color_format="RGB")
self.client.set_user_name(self.bot_name)
self.client.join(self.room_url, self.token)
self.my_participant_id = self.client.participants()['local']['id']
self.client.start_transcription()
def on_participant_joined(self, participant):
self.client.send_app_message({ "event": "story-id", "storyID": self.story_id})
self.wave()
time.sleep(2)
# don't run intro question for newcomers
if not self.story_started:
#self.orchestrator.request_intro()
self.orchestrator.action()
self.story_started = True
def on_transcription_message(self, message):
if message['session_id'] != self.my_participant_id:
if self.orchestrator.started_listening_at:
self.transcription += f" {message['text']}"
if re.search(r'[\.\!\?]$', self.transcription):
print(f"✏️ Sending reply: {self.transcription}")
self.orchestrator.handle_user_speech(self.transcription)
self.transcription = ""
else:
print(f"✏️ Got a transcription fragment, waiting for complete sentence: \"{self.transcription}\"")Here’s what the flow of data in the storybot demo looks like.
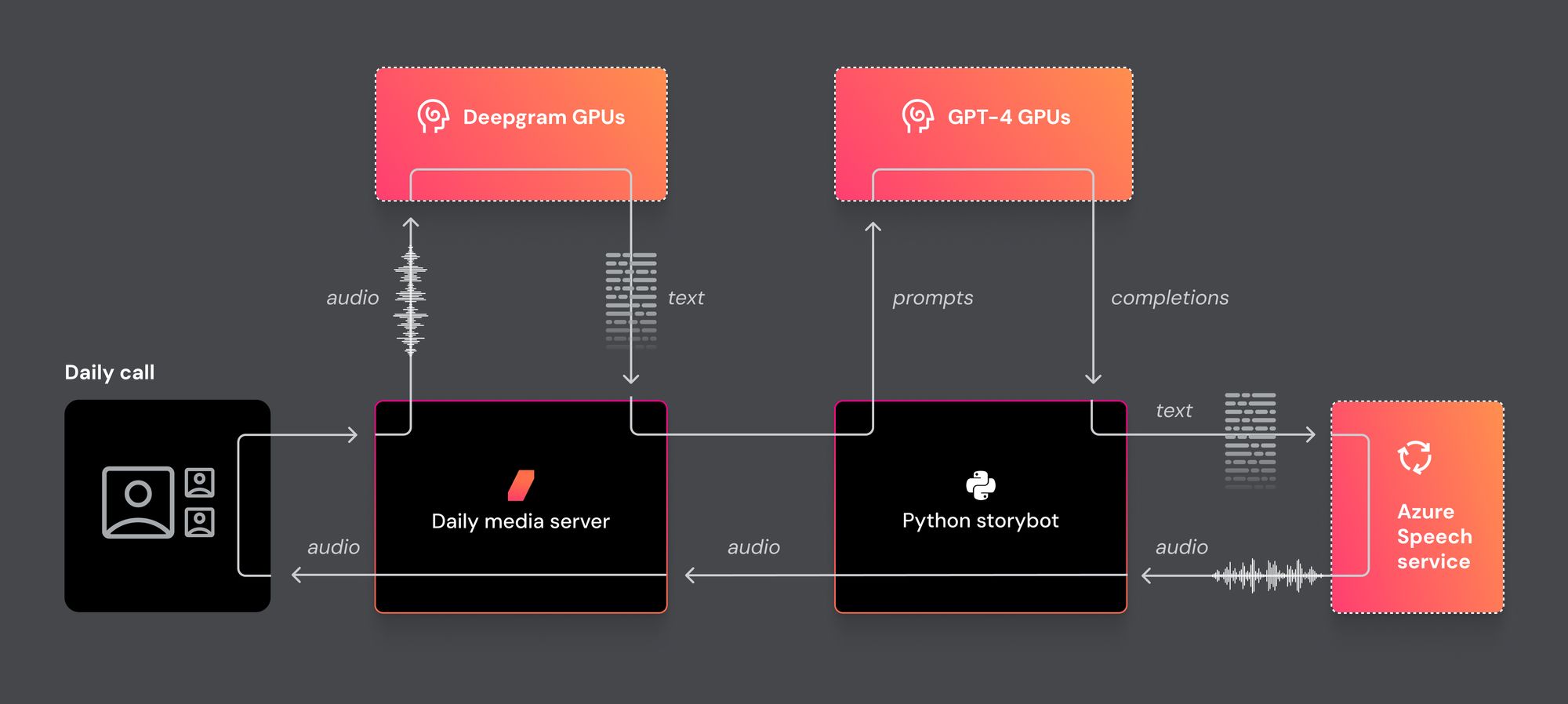
Our goal is for the llm-talk code to be a complete starting point for your apps, and for the orchestrator layer to take care of all the low-level glue, so that you can focus on writing the actual application that you’re imagining! As usually happens with a project like this, we've accumulated a pretty good backlog of improvements we want to make and extensions we want to add. And we're committed to supporting voice-driven and speech-to-speech apps. So expect regular updates to this code.
AI progress is happening very fast. We expect to see a lot of experimentation and innovation around voice interfaces, because the new capabilities of today’s speech recognition, large language model, and speech synthesis technologies are so impressive and complement each other so well.
Here’s a voice-driven LLM application that I’d like to use: I want to talk – literally – to The New York Times or The Wall Street Journal. I grew up in a household that subscribed to multiple daily newspapers. I love newspapers! But these days I rarely read the paper the old fashioned way. (The San Francisco Chronicle won’t even deliver a physical paper to my house. And I live in a residential neighborhood in San Francisco.)
Increasingly, I think that individual news stories posted to the web or embedded in an app feel like they’re an old format, incompletely ported to a new platform. Last month, I wanted to ask the New York Times about the ARM IPO and get a short, current summary about what had happened on the first day of trading, then follow up with my own questions.
The collective knowledge of the Times beat reporters and the paper’s decades-spanning archive are both truly amazing. The talking heads shows on TV kind of do what I want, but with the show hosts as a proxy for me and a Times reporter as a proxy for the New York Times. I don’t want anyone to proxy for me; I want to ask questions myself. An LLM could be a gateway providing nonlinear access to the treasure trove that is The Grey Lady’s institutional memory. (Also, I want to navigate through this treasure trove conversationally, while cooking dinner or doing laundry.)
What new, voice-driven applications are you excited about? Our favorite thing at Daily is that we get to see all sorts of amazing things that developers create with the tools we’ve built. If you’ve got an app that uses real-time speech in a new way, or ideas you’re excited about, or questions, please ping us on social media, join us on Discord, or find us online or IRL at one of the events we host.
Never miss a story
Get the latest direct to your inbox.